Solutions 2: Exploratory Analysis of Bayesian models#
import numpy as np
import pymc3 as pm
import arviz as az
import matplotlib.pyplot as plt
from scipy import stats
az.style.use("arviz-darkgrid")
np.random.seed(521)
rng = np.random.RandomState(2021)
viridish = [(0.2823529411764706, 0.11372549019607843, 0.43529411764705883, 1.0),
(0.1450980392156863, 0.6705882352941176, 0.5098039215686274, 1.0),
(0.6901960784313725, 0.8666666666666667, 0.1843137254901961, 1.0)]
2E1#
Using your own words, what are the main differences between prior predictive checks and posterior predictive checks? How are these empirical evaluations related to Equations (1.7) and (1.8).
Prior predictive checks primarily assess the plausibility of parameters prior to seeing the data at hand. They do this through generating samples of what we think will be observed, as encoded in our model. We can then compare these samples with our domain knowledge to note any discrepancies. Additionally, prior predictive checks are useful in computational Bayesian statistics to ensure models syntax is correct, e.g. no shape issues etc, and models are semantically correct, we wrote the intended model.
Posterior predictive samples are predictions from our model, i.e. what we think will be observed. We can compare the posterior predictive values with the observed data to note any discrepancies.
These relate to Equations 1.7 and 1.8 in that the equations are the definition of the prior predictive and posterior predictive distributions. We base prior/posterior predictive checks on the ability to compute those distributions.
2E2#
Using your own words explain: ESS, \(\hat R\) and MCSE. Focus your explanation on what these quantities are measuring and what potential issue with MCMC they are identifying.
ESS is measuring the number of effective samples in the MCMC chain by assessing the autocorrelation between samples. Highly autocorrelated chains will tend to have less information about the posterior distribution than lesser autocorrelated chains
\(\hat R\) measures the ratio of in-chain variance versus the between-chain variance for all chains. If the between-chain variance tends to be close to the in-chain variance we can be more confident that the chains have converged to the same posterior distribution. If the \(\hat R\) value is high, then we know that the chains have likely not converged and that the samples may be biased. In practice we used the value 1.01 as the cutoff value
MCSE is an estimate of the inaccuracy of Monte Carlo samples. Recall that MCMC, for any finite sample, is an approximation, so MCSE helps quantify the error introduced by that approximation, given there were no sampling issues indicated by ESS or \(\hat R\)
2E3 Reword#
ArviZ includes precomputed InferenceData objects for a few models. We are going to load an InferenceData object generated from a classical example in Bayesian statistic, the eight schools model. The InferenceData object includes prior samples, prior predictive samples and posterior samples. We can load the InferenceData object using the command az.load_arviz_data(“centered_eight”). Use ArviZ to:
a. List all the groups available on the InferenceData object.
b. Identify the number of chains and the total number of posterior samples.
c. Plot the posterior.
d. Plot the posterior predictive distribution.
e. Calculate the estimated mean of the parameters, and the Highest Density Intervals.
eight_schools_inf_data = az.load_arviz_data("centered_eight")
Solution a#
When working with jupyter notebook we can get a hmtl-pretty-print justby doing:
eight_schools_inf_data
-
- chain: 4
- draw: 500
- school: 8
- chain(chain)int640 1 2 3
array([0, 1, 2, 3])
- draw(draw)int640 1 2 3 4 5 ... 495 496 497 498 499
array([ 0, 1, 2, ..., 497, 498, 499])
- school(school)object'Choate' ... 'Mt. Hermon'
array(['Choate', 'Deerfield', 'Phillips Andover', 'Phillips Exeter', 'Hotchkiss', 'Lawrenceville', "St. Paul's", 'Mt. Hermon'], dtype=object)
- mu(chain, draw)float64...
array([[-3.476986, -2.455871, -2.826254, ..., 3.392022, 8.46255 , -0.238516], [ 8.250863, 8.250863, 8.250863, ..., 2.527095, 0.276589, 5.655297], [10.51707 , 9.887949, 8.500833, ..., -1.571177, -4.435385, 9.762948], [ 4.532296, 4.532296, 3.914097, ..., 4.597058, 5.898506, 0.161389]]) - theta(chain, draw, school)float64...
array([[[ 1.668654, -8.537401, ..., 0.155234, -6.818251], [-6.239359, 1.071411, ..., -4.462528, -1.110761], ..., [ 9.292977, 13.691033, ..., 8.176874, 5.888367], [11.715418, 4.492172, ..., 12.300712, 9.22107 ]], [[ 8.096212, 7.756517, ..., 6.465884, 5.472468], [ 8.096212, 7.756517, ..., 6.465884, 5.472468], ..., [14.735501, 7.546139, ..., 15.732696, -4.697359], [-4.837035, 8.501408, ..., 5.850945, -0.426543]], [[14.570919, 15.029668, ..., 11.798422, 8.519339], [12.686667, 7.679173, ..., 13.514133, 10.295221], ..., [ 5.361653, 2.78173 , ..., 7.224553, -7.416111], [13.439111, 9.614329, ..., 12.008359, 16.673157]], [[ 4.326388, 5.198464, ..., 5.339654, 3.422931], [ 4.326388, 5.198464, ..., 5.339654, 3.422931], ..., [-1.420946, -4.034405, ..., 15.850648, 4.013397], [-0.050159, 0.063538, ..., 10.592933, 4.523389]]]) - tau(chain, draw)float64...
array([[ 3.730101, 2.075383, 3.702993, ..., 10.107925, 8.079994, 7.728861], [ 1.193334, 1.193334, 1.193334, ..., 13.922048, 8.869919, 4.763175], [ 5.137247, 4.264381, 2.141432, ..., 2.811842, 12.179657, 4.452967], [ 0.50007 , 0.50007 , 0.902267, ..., 8.345631, 7.71079 , 5.406798]])
- created_at :
- 2019-06-21T17:36:34.398087
- inference_library :
- pymc3
- inference_library_version :
- 3.7
<xarray.Dataset> Dimensions: (chain: 4, draw: 500, school: 8) Coordinates: * chain (chain) int64 0 1 2 3 * draw (draw) int64 0 1 2 3 4 5 6 7 8 ... 492 493 494 495 496 497 498 499 * school (school) object 'Choate' 'Deerfield' ... "St. Paul's" 'Mt. Hermon' Data variables: mu (chain, draw) float64 -3.477 -2.456 -2.826 ... 4.597 5.899 0.1614 theta (chain, draw, school) float64 1.669 -8.537 -2.623 ... 10.59 4.523 tau (chain, draw) float64 3.73 2.075 3.703 4.146 ... 8.346 7.711 5.407 Attributes: created_at: 2019-06-21T17:36:34.398087 inference_library: pymc3 inference_library_version: 3.7xarray.Dataset -
- chain: 4
- draw: 500
- school: 8
- chain(chain)int640 1 2 3
array([0, 1, 2, 3])
- draw(draw)int640 1 2 3 4 5 ... 495 496 497 498 499
array([ 0, 1, 2, ..., 497, 498, 499])
- school(school)object'Choate' ... 'Mt. Hermon'
array(['Choate', 'Deerfield', 'Phillips Andover', 'Phillips Exeter', 'Hotchkiss', 'Lawrenceville', "St. Paul's", 'Mt. Hermon'], dtype=object)
- obs(chain, draw, school)float64...
array([[[ 7.850329e+00, -1.902792e+01, ..., -3.547030e+00, 1.619463e+01], [ 2.931985e+00, 1.919950e-01, ..., -8.065696e-01, 1.518667e+01], ..., [-7.248618e-01, 5.924768e+00, ..., 1.173805e+01, -1.422732e+01], [ 2.220263e+01, 1.548817e+01, ..., 8.783500e+00, 2.019629e+01]], [[-1.202312e+01, 1.233019e+01, ..., 2.131579e+01, 8.356886e+00], [ 4.996825e+00, 1.506829e+01, ..., -1.342830e+00, -2.743757e+01], ..., [ 3.666123e+01, 1.349807e+01, ..., 4.540989e+01, -2.117575e+00], [ 1.791875e+00, 1.501421e+01, ..., -2.182083e+00, -6.630969e+00]], [[ 3.377648e+01, 3.088294e+01, ..., 2.182889e+01, 4.625301e+00], [-5.600531e-01, 5.228436e+00, ..., 9.387947e+00, 3.665830e+00], ..., [ 3.279823e+00, -1.301396e+01, ..., 1.089418e+01, -1.149742e+01], [ 3.424522e+01, 2.320377e+01, ..., 9.892069e+00, 1.729264e+01]], [[-1.517826e-02, -5.597241e-01, ..., -2.986433e+00, 1.075464e+01], [ 7.538687e+00, 2.524281e+01, ..., -8.230382e+00, -2.109873e+01], ..., [ 2.180411e+00, -1.861976e+01, ..., 2.564547e+01, -7.993703e+00], [-2.096968e+01, 5.474909e+00, ..., 4.697547e+00, -1.506955e+01]]])
- created_at :
- 2019-06-21T17:36:34.489022
- inference_library :
- pymc3
- inference_library_version :
- 3.7
<xarray.Dataset> Dimensions: (chain: 4, draw: 500, school: 8) Coordinates: * chain (chain) int64 0 1 2 3 * draw (draw) int64 0 1 2 3 4 5 6 7 8 ... 492 493 494 495 496 497 498 499 * school (school) object 'Choate' 'Deerfield' ... "St. Paul's" 'Mt. Hermon' Data variables: obs (chain, draw, school) float64 7.85 -19.03 -22.5 ... 4.698 -15.07 Attributes: created_at: 2019-06-21T17:36:34.489022 inference_library: pymc3 inference_library_version: 3.7xarray.Dataset -
- chain: 4
- draw: 500
- school: 8
- chain(chain)int640 1 2 3
array([0, 1, 2, 3])
- draw(draw)int640 1 2 3 4 5 ... 495 496 497 498 499
array([ 0, 1, 2, ..., 497, 498, 499])
- school(school)object'Choate' ... 'Mt. Hermon'
array(['Choate', 'Deerfield', 'Phillips Andover', 'Phillips Exeter', 'Hotchkiss', 'Lawrenceville', "St. Paul's", 'Mt. Hermon'], dtype=object)
- tune(chain, draw)bool...
array([[ True, False, False, ..., False, False, False], [ True, False, False, ..., False, False, False], [ True, False, False, ..., False, False, False], [ True, False, False, ..., False, False, False]]) - depth(chain, draw)int64...
array([[5, 3, 3, ..., 5, 5, 4], [6, 3, 2, ..., 4, 4, 4], [3, 5, 3, ..., 4, 4, 5], [3, 4, 3, ..., 5, 5, 5]]) - tree_size(chain, draw)float64...
array([[31., 7., 7., ..., 31., 31., 15.], [39., 7., 3., ..., 15., 15., 15.], [ 7., 31., 7., ..., 15., 15., 31.], [ 7., 11., 7., ..., 31., 31., 31.]]) - lp(chain, draw)float64...
array([[-59.048452, -56.192829, -56.739609, ..., -63.171891, -62.871221, -59.67573 ], [-51.16655 , -51.16655 , -51.16655 , ..., -62.242981, -60.962775, -61.120349], [-57.1196 , -54.709673, -49.854318, ..., -58.202845, -63.100613, -61.906641], [-43.11603 , -43.11603 , -44.766386, ..., -60.530643, -63.616474, -58.345072]]) - energy_error(chain, draw)float64...
array([[ 0.073872, -0.184094, 0.301398, ..., -0.024763, 0.015377, 0.011884], [ 0.542861, 0. , 0. , ..., 0.035578, -0.144987, -0.023558], [ 1.30834 , -0.068309, -0.343327, ..., -0.480097, 1.118238, -0.505195], [-0.232345, 0. , 2.427791, ..., -0.007677, -0.087005, -0.003652]]) - step_size_bar(chain, draw)float64...
array([[0.241676, 0.241676, 0.241676, ..., 0.241676, 0.241676, 0.241676], [0.233163, 0.233163, 0.233163, ..., 0.233163, 0.233163, 0.233163], [0.25014 , 0.25014 , 0.25014 , ..., 0.25014 , 0.25014 , 0.25014 ], [0.150248, 0.150248, 0.150248, ..., 0.150248, 0.150248, 0.150248]]) - max_energy_error(chain, draw)float64...
array([[ 1.310060e-01, -2.066764e-01, 6.362023e-01, ..., 1.272182e-01, -3.155631e-01, -6.702092e-02], [ 2.089505e+00, 3.848563e+01, 6.992369e+01, ..., -3.713299e-01, -2.177462e-01, -1.621819e-01], [ 1.458063e+00, 4.335779e+02, 2.788723e+00, ..., -4.800969e-01, 4.380251e+00, -5.051946e-01], [ 3.226553e-01, 2.736452e+02, 2.202908e+02, ..., -1.224747e-01, -1.009818e-01, -1.756579e-01]]) - energy(chain, draw)float64...
array([[60.756731, 62.756232, 64.398717, ..., 67.394493, 66.923554, 65.031815], [53.535435, 56.914649, 54.576739, ..., 63.760659, 64.405753, 66.210544], [62.504616, 61.998659, 56.945798, ..., 64.477622, 68.892486, 67.322436], [50.115409, 46.916088, 52.915592, ..., 66.27361 , 67.768307, 67.209852]]) - mean_tree_accept(chain, draw)float64...
array([[0.950641, 0.990596, 0.725287, ..., 0.971847, 0.979623, 0.986629], [0.78913 , 0.014034, 0.035809, ..., 0.989669, 0.987006, 0.991768], [0.26802 , 0.392567, 0.839235, ..., 0.969229, 0.105422, 0.979116], [0.909964, 0.157585, 0.061793, ..., 0.999467, 0.987537, 0.996704]]) - step_size(chain, draw)float64...
array([[0.127504, 0.127504, 0.127504, ..., 0.127504, 0.127504, 0.127504], [0.12298 , 0.12298 , 0.12298 , ..., 0.12298 , 0.12298 , 0.12298 ], [0.207479, 0.207479, 0.207479, ..., 0.207479, 0.207479, 0.207479], [0.106445, 0.106445, 0.106445, ..., 0.106445, 0.106445, 0.106445]]) - diverging(chain, draw)bool...
array([[False, False, False, ..., False, False, False], [False, False, False, ..., False, False, False], [False, False, False, ..., False, False, False], [False, False, False, ..., False, False, False]]) - log_likelihood(chain, draw, school)float64...
array([[[-5.167744, -4.588952, ..., -4.813702, -4.355802], [-6.232175, -3.46155 , ..., -5.744349, -4.074576], ..., [-4.404661, -3.383463, ..., -3.703993, -3.866952], [-4.216295, -3.283048, ..., -3.383933, -3.821228]], [[-4.507346, -3.22182 , ..., -3.886703, -3.875064], [-4.507346, -3.22182 , ..., -3.886703, -3.875064], ..., [-4.017982, -3.222554, ..., -3.247227, -4.23956 ], [-6.023146, -3.222781, ..., -3.959521, -4.047611]], [[-4.027745, -3.468605, ..., -3.413821, -3.828006], [-4.148096, -3.222038, ..., -3.322139, -3.813795], ..., [-4.765866, -3.357675, ..., -3.802075, -4.391078], [-4.098143, -3.234554, ..., -3.401022, -3.843012]], [[-4.872411, -3.260767, ..., -4.022945, -3.922838], [-4.872411, -3.260767, ..., -4.022945, -3.922838], ..., [-5.550527, -3.945658, ..., -3.244622, -3.907745], [-5.375459, -3.536461, ..., -3.495847, -3.895575]]])
- created_at :
- 2019-06-21T17:36:34.485802
- inference_library :
- pymc3
- inference_library_version :
- 3.7
<xarray.Dataset> Dimensions: (chain: 4, draw: 500, school: 8) Coordinates: * chain (chain) int64 0 1 2 3 * draw (draw) int64 0 1 2 3 4 5 6 ... 493 494 495 496 497 498 499 * school (school) object 'Choate' 'Deerfield' ... 'Mt. Hermon' Data variables: tune (chain, draw) bool True False False ... False False False depth (chain, draw) int64 5 3 3 4 5 5 4 4 5 ... 4 4 4 5 5 5 5 5 tree_size (chain, draw) float64 31.0 7.0 7.0 15.0 ... 31.0 31.0 31.0 lp (chain, draw) float64 -59.05 -56.19 ... -63.62 -58.35 energy_error (chain, draw) float64 0.07387 -0.1841 ... -0.087 -0.003652 step_size_bar (chain, draw) float64 0.2417 0.2417 ... 0.1502 0.1502 max_energy_error (chain, draw) float64 0.131 -0.2067 ... -0.101 -0.1757 energy (chain, draw) float64 60.76 62.76 64.4 ... 67.77 67.21 mean_tree_accept (chain, draw) float64 0.9506 0.9906 ... 0.9875 0.9967 step_size (chain, draw) float64 0.1275 0.1275 ... 0.1064 0.1064 diverging (chain, draw) bool False False False ... False False False log_likelihood (chain, draw, school) float64 -5.168 -4.589 ... -3.896 Attributes: created_at: 2019-06-21T17:36:34.485802 inference_library: pymc3 inference_library_version: 3.7xarray.Dataset -
- chain: 1
- draw: 500
- school: 8
- chain(chain)int640
array([0])
- draw(draw)int640 1 2 3 4 5 ... 495 496 497 498 499
array([ 0, 1, 2, ..., 497, 498, 499])
- school(school)object'Choate' ... 'Mt. Hermon'
array(['Choate', 'Deerfield', 'Phillips Andover', 'Phillips Exeter', 'Hotchkiss', 'Lawrenceville', "St. Paul's", 'Mt. Hermon'], dtype=object)
- tau(chain, draw)float64...
array([[ 6.560633, 1.016055, 68.91391 , ..., 1.560098, 5.948734, 0.763063]])
- tau_log__(chain, draw)float64...
array([[ 1.881087, 0.015927, 4.232858, ..., 0.444748, 1.783178, -0.270415]])
- mu(chain, draw)float64...
array([[ 5.29345 , 0.813724, 0.712223, ..., -0.979857, -1.657547, -3.272668]])
- theta(chain, draw, school)float64...
array([[[ 2.357357, 7.371371, ..., 6.135082, 3.984435], [ 0.258399, -0.752515, ..., 1.73084 , -0.034163], ..., [-4.353289, 2.194643, ..., -7.819076, -6.21613 ], [-4.131344, -4.093318, ..., -3.775218, -3.555126]]]) - obs(chain, draw, school)float64...
array([[[ -3.539971, 6.769448, ..., 8.26964 , -8.569042], [-21.166369, 1.14605 , ..., -13.157913, -8.5424 ], ..., [ 29.354582, -5.511382, ..., -17.892521, 46.28878 ], [ -6.379747, 6.538907, ..., -21.155214, -6.070767]]])
- created_at :
- 2019-06-21T17:36:34.490387
- inference_library :
- pymc3
- inference_library_version :
- 3.7
<xarray.Dataset> Dimensions: (chain: 1, draw: 500, school: 8) Coordinates: * chain (chain) int64 0 * draw (draw) int64 0 1 2 3 4 5 6 7 ... 492 493 494 495 496 497 498 499 * school (school) object 'Choate' 'Deerfield' ... 'Mt. Hermon' Data variables: tau (chain, draw) float64 6.561 1.016 68.91 ... 1.56 5.949 0.7631 tau_log__ (chain, draw) float64 1.881 0.01593 4.233 ... 1.783 -0.2704 mu (chain, draw) float64 5.293 0.8137 0.7122 ... -1.658 -3.273 theta (chain, draw, school) float64 2.357 7.371 7.251 ... -3.775 -3.555 obs (chain, draw, school) float64 -3.54 6.769 19.68 ... -21.16 -6.071 Attributes: created_at: 2019-06-21T17:36:34.490387 inference_library: pymc3 inference_library_version: 3.7xarray.Dataset -
- school: 8
- school(school)object'Choate' ... 'Mt. Hermon'
array(['Choate', 'Deerfield', 'Phillips Andover', 'Phillips Exeter', 'Hotchkiss', 'Lawrenceville', "St. Paul's", 'Mt. Hermon'], dtype=object)
- obs(school)float64...
array([28., 8., -3., 7., -1., 1., 18., 12.])
- created_at :
- 2019-06-21T17:36:34.491909
- inference_library :
- pymc3
- inference_library_version :
- 3.7
<xarray.Dataset> Dimensions: (school: 8) Coordinates: * school (school) object 'Choate' 'Deerfield' ... "St. Paul's" 'Mt. Hermon' Data variables: obs (school) float64 28.0 8.0 -3.0 7.0 -1.0 1.0 18.0 12.0 Attributes: created_at: 2019-06-21T17:36:34.491909 inference_library: pymc3 inference_library_version: 3.7xarray.Dataset
And we can also get the group names as a list of strings
eight_schools_inf_data.groups()
['posterior', 'posterior_predictive', 'sample_stats', 'prior', 'observed_data']
Solution b#
The chains and draws are listed as (chain: 4, draw: 500, school: 8)
eight_schools_inf_data.posterior
<xarray.Dataset>
Dimensions: (chain: 4, draw: 500, school: 8)
Coordinates:
* chain (chain) int64 0 1 2 3
* draw (draw) int64 0 1 2 3 4 5 6 7 8 ... 492 493 494 495 496 497 498 499
* school (school) object 'Choate' 'Deerfield' ... "St. Paul's" 'Mt. Hermon'
Data variables:
mu (chain, draw) float64 -3.477 -2.456 -2.826 ... 4.597 5.899 0.1614
theta (chain, draw, school) float64 1.669 -8.537 -2.623 ... 10.59 4.523
tau (chain, draw) float64 3.73 2.075 3.703 4.146 ... 8.346 7.711 5.407
Attributes:
created_at: 2019-06-21T17:36:34.398087
inference_library: pymc3
inference_library_version: 3.7- chain: 4
- draw: 500
- school: 8
- chain(chain)int640 1 2 3
array([0, 1, 2, 3])
- draw(draw)int640 1 2 3 4 5 ... 495 496 497 498 499
array([ 0, 1, 2, ..., 497, 498, 499])
- school(school)object'Choate' ... 'Mt. Hermon'
array(['Choate', 'Deerfield', 'Phillips Andover', 'Phillips Exeter', 'Hotchkiss', 'Lawrenceville', "St. Paul's", 'Mt. Hermon'], dtype=object)
- mu(chain, draw)float64-3.477 -2.456 ... 5.899 0.1614
array([[-3.476986, -2.455871, -2.826254, ..., 3.392022, 8.46255 , -0.238516], [ 8.250863, 8.250863, 8.250863, ..., 2.527095, 0.276589, 5.655297], [10.51707 , 9.887949, 8.500833, ..., -1.571177, -4.435385, 9.762948], [ 4.532296, 4.532296, 3.914097, ..., 4.597058, 5.898506, 0.161389]]) - theta(chain, draw, school)float641.669 -8.537 -2.623 ... 10.59 4.523
array([[[ 1.668654, -8.537401, ..., 0.155234, -6.818251], [-6.239359, 1.071411, ..., -4.462528, -1.110761], ..., [ 9.292977, 13.691033, ..., 8.176874, 5.888367], [11.715418, 4.492172, ..., 12.300712, 9.22107 ]], [[ 8.096212, 7.756517, ..., 6.465884, 5.472468], [ 8.096212, 7.756517, ..., 6.465884, 5.472468], ..., [14.735501, 7.546139, ..., 15.732696, -4.697359], [-4.837035, 8.501408, ..., 5.850945, -0.426543]], [[14.570919, 15.029668, ..., 11.798422, 8.519339], [12.686667, 7.679173, ..., 13.514133, 10.295221], ..., [ 5.361653, 2.78173 , ..., 7.224553, -7.416111], [13.439111, 9.614329, ..., 12.008359, 16.673157]], [[ 4.326388, 5.198464, ..., 5.339654, 3.422931], [ 4.326388, 5.198464, ..., 5.339654, 3.422931], ..., [-1.420946, -4.034405, ..., 15.850648, 4.013397], [-0.050159, 0.063538, ..., 10.592933, 4.523389]]]) - tau(chain, draw)float643.73 2.075 3.703 ... 7.711 5.407
array([[ 3.730101, 2.075383, 3.702993, ..., 10.107925, 8.079994, 7.728861], [ 1.193334, 1.193334, 1.193334, ..., 13.922048, 8.869919, 4.763175], [ 5.137247, 4.264381, 2.141432, ..., 2.811842, 12.179657, 4.452967], [ 0.50007 , 0.50007 , 0.902267, ..., 8.345631, 7.71079 , 5.406798]])
- created_at :
- 2019-06-21T17:36:34.398087
- inference_library :
- pymc3
- inference_library_version :
- 3.7
One way to get the number of samples is:
len(eight_schools_inf_data.posterior.chain) * len(eight_schools_inf_data.posterior.draw)
2000
Solution c#
There are many ways to represent the posterior, one is
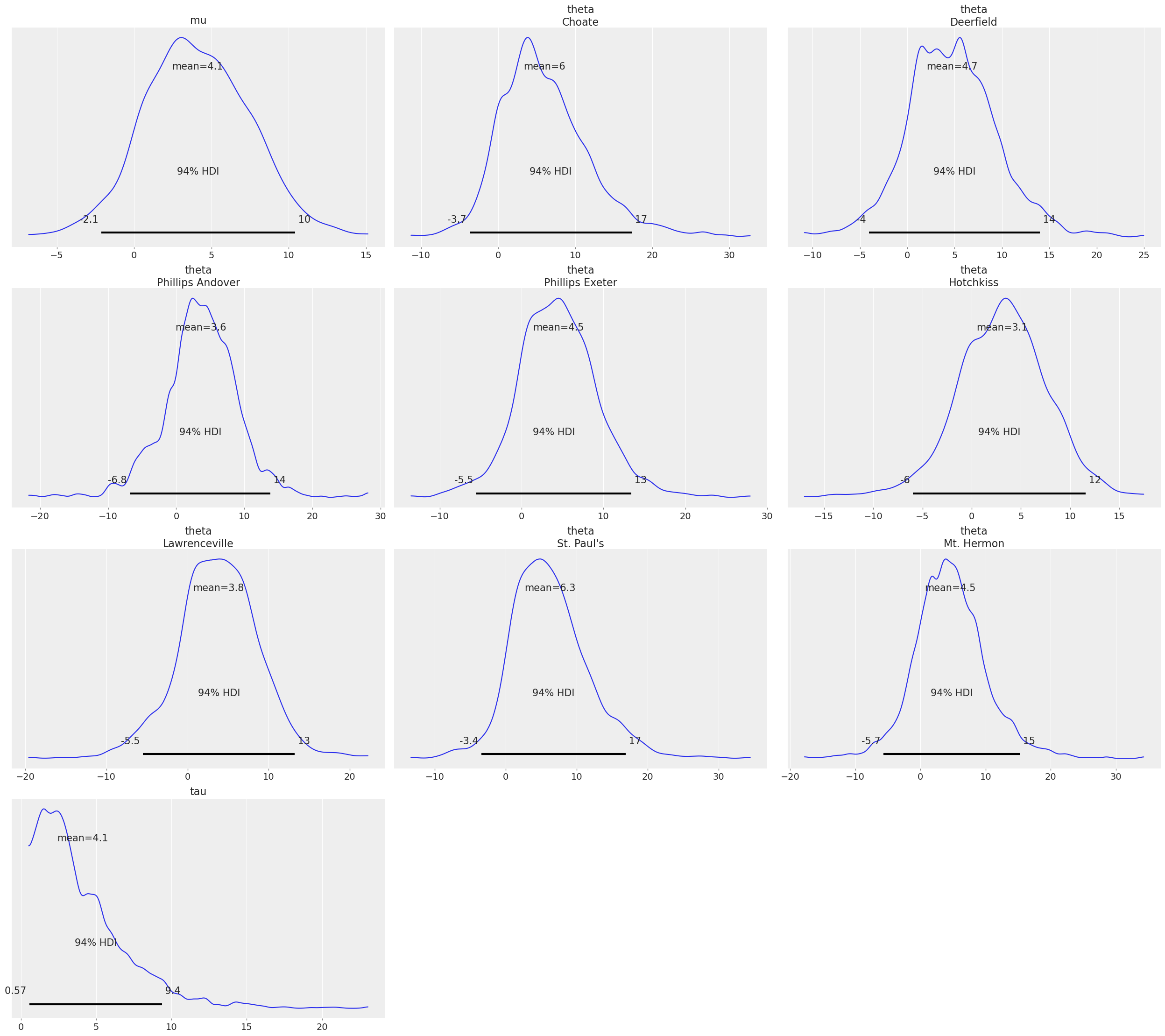
az.plot_posterior(eight_schools_inf_data);
Solution D#
az.plot_ppc(eight_schools_inf_data);
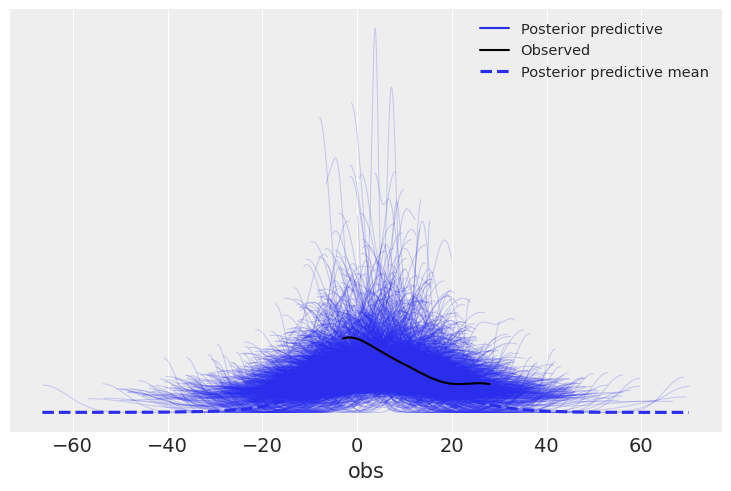
Solution e#
We can call summary, and optionally subset the resulting dataframe to display just the needed information
az.summary(eight_schools_inf_data)[["mean", "hdi_3%", "hdi_97%"]]
| mean | hdi_3% | hdi_97% | |
|---|---|---|---|
| mu | 4.093 | -2.118 | 10.403 |
| theta[0] | 6.026 | -3.707 | 17.337 |
| theta[1] | 4.724 | -4.039 | 13.999 |
| theta[2] | 3.576 | -6.779 | 13.838 |
| theta[3] | 4.478 | -5.528 | 13.392 |
| theta[4] | 3.064 | -5.972 | 11.547 |
| theta[5] | 3.821 | -5.507 | 13.232 |
| theta[6] | 6.250 | -3.412 | 16.920 |
| theta[7] | 4.544 | -5.665 | 15.266 |
| tau | 4.089 | 0.569 | 9.386 |
We can call also pass a dictionary with names and function to az.summary like this:
func_dict = {"mean": np.mean,
"hdi_3%": lambda x: az.hdi(x)[0],
"hdi_97%": lambda x: az.hdi(x)[1],
}
az.summary(eight_schools_inf_data, extend=False, stat_funcs=func_dict)
| mean | hdi_3% | hdi_97% | |
|---|---|---|---|
| mu | 4.093 | -2.118 | 10.403 |
| theta[0] | 6.026 | -3.707 | 17.337 |
| theta[1] | 4.724 | -4.039 | 13.999 |
| theta[2] | 3.576 | -6.779 | 13.838 |
| theta[3] | 4.478 | -5.528 | 13.392 |
| theta[4] | 3.064 | -5.972 | 11.547 |
| theta[5] | 3.821 | -5.507 | 13.232 |
| theta[6] | 6.250 | -3.412 | 16.920 |
| theta[7] | 4.544 | -5.665 | 15.266 |
| tau | 4.089 | 0.569 | 9.386 |
2E4#
Load az.load_arviz_data(“non_centered_eight”), which is a reparametrized version of the “centered_eight” model in the previous exercise. Use ArviZ to assess the MCMC sampling convergence for both models by using:
a. Autocorrelation plots
b. Rank plots
c. \(\hat R\) values
Focus on the plots for the mu and tau parameters. What do these three different diagnostics show? Compare these to the InferenceData results loaded from az.load_arviz_data(“centered_eight”). Do all three diagnostics tend to agree on which model is preferred? Which one of the models has better convergence diagnostics?
non_centered = az.load_arviz_data("non_centered_eight")
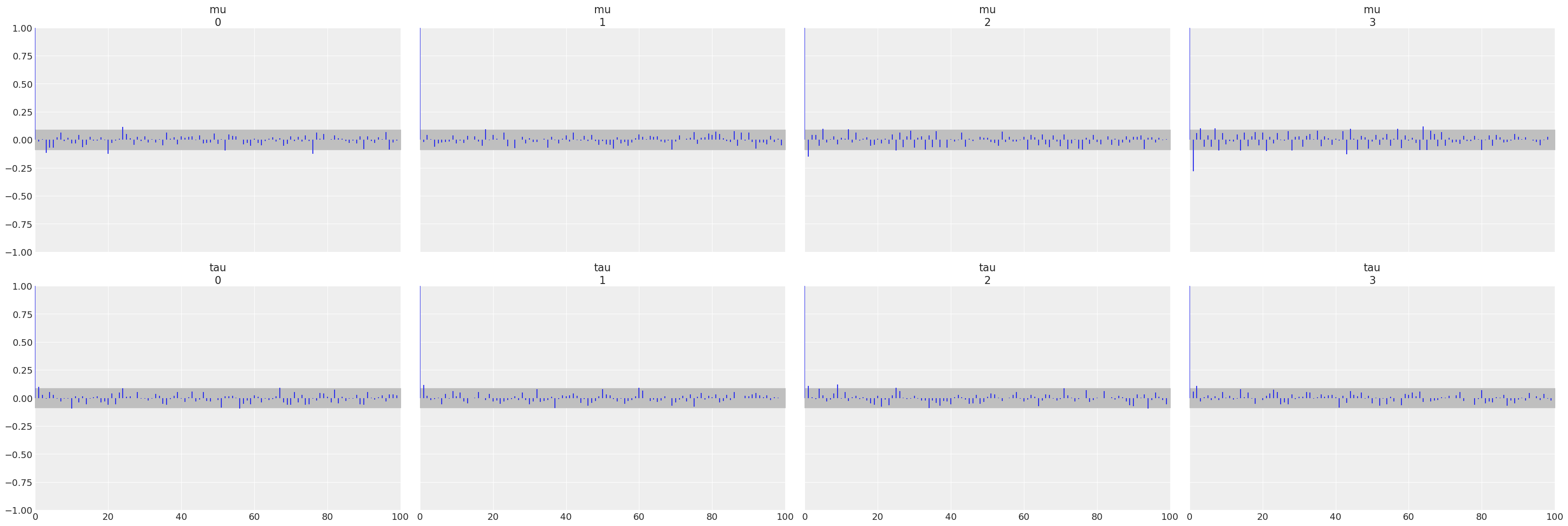
az.plot_autocorr(non_centered, var_names=["mu", "tau"]);
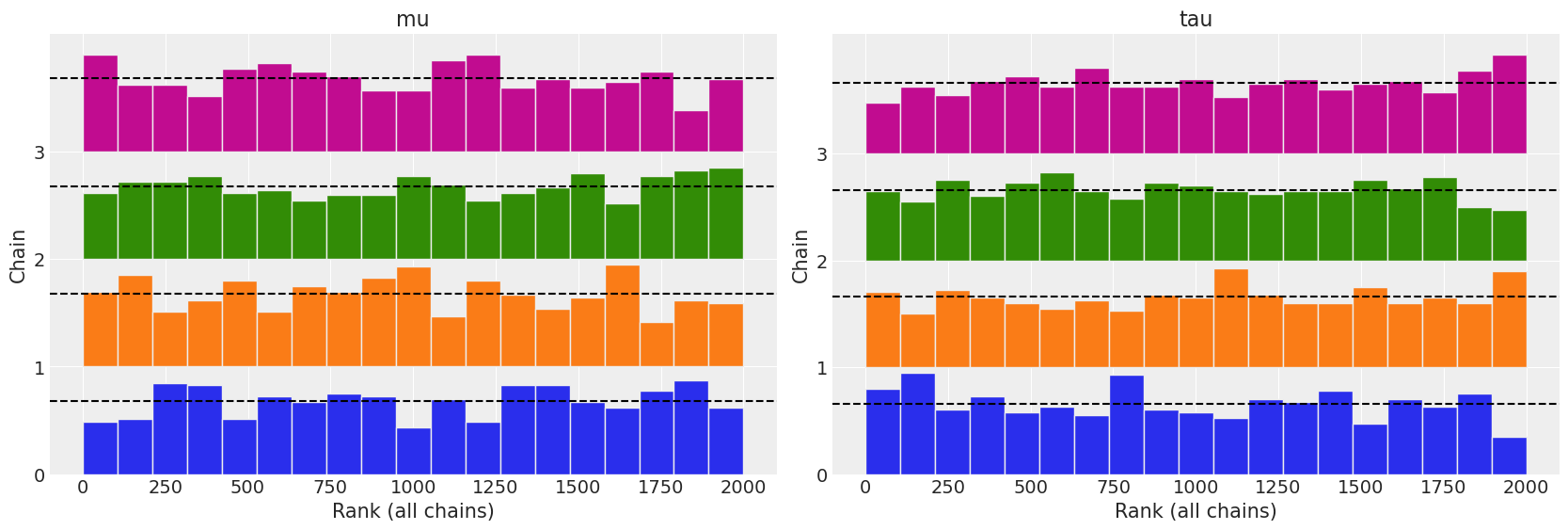
az.plot_rank(non_centered, var_names=["mu", "tau"]);
az.rhat(non_centered, var_names=["mu", "tau"])
<xarray.Dataset>
Dimensions: ()
Data variables:
mu float64 1.0
tau float64 1.001- mu()float641.0
array(1.00014037)
- tau()float641.001
array(1.0007566)
centered = az.load_arviz_data("centered_eight")
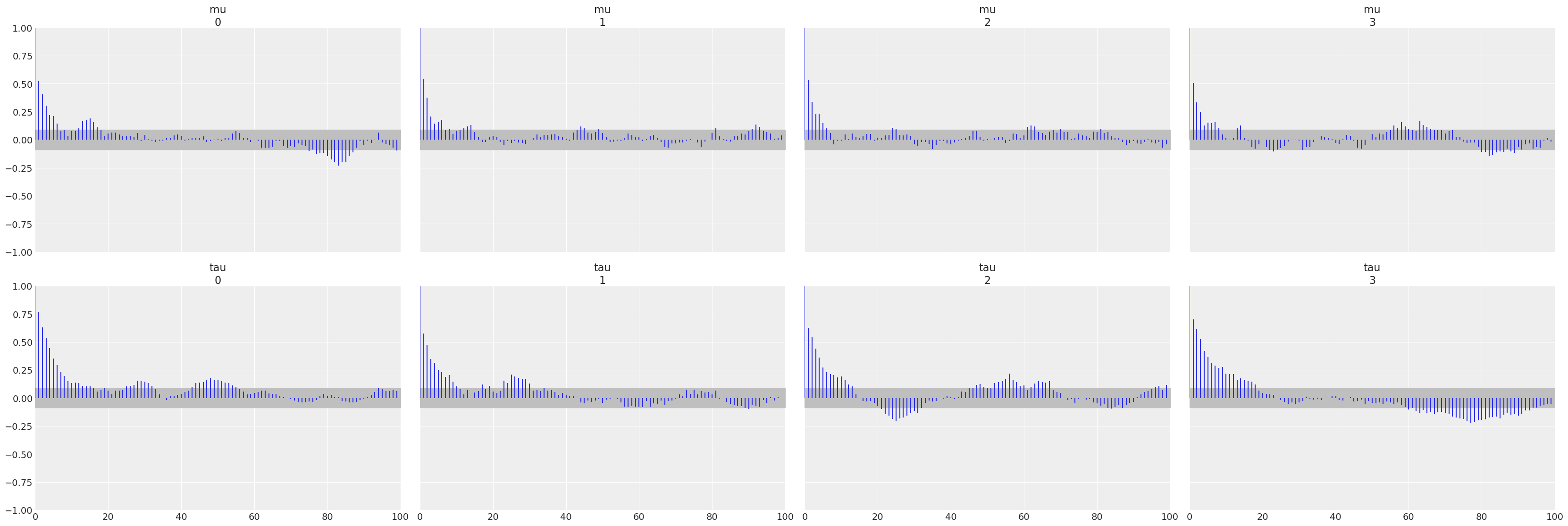
az.plot_autocorr(centered, var_names=["mu", "tau"]);
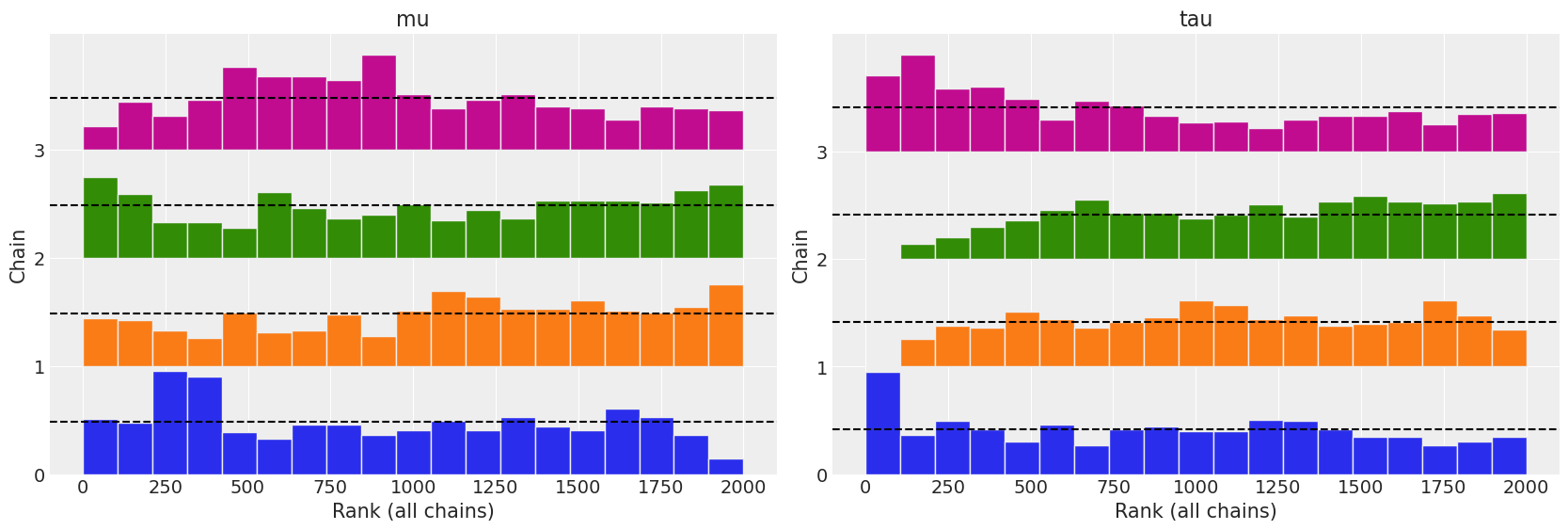
az.plot_rank(centered, var_names=["mu", "tau"]);
az.rhat(centered, var_names=["mu", "tau"])
<xarray.Dataset>
Dimensions: ()
Data variables:
mu float64 1.027
tau float64 1.071- mu()float641.027
array(1.02725234)
- tau()float641.071
array(1.07072754)
All three diagnostics tend to indicate the non centered model is preferred. The autocorrelation plots show a faster reduction to zero, rank plots are more uniform, and the \(\hat R\) values are closer to 1.
2E5#
InferenceData object can store statistics related to the sampling algorithm. You will find them in the sample_stats group, including divergences (diverging):
a. Count the number of divergences for “centered_eight” and “non_centered_eight” models.
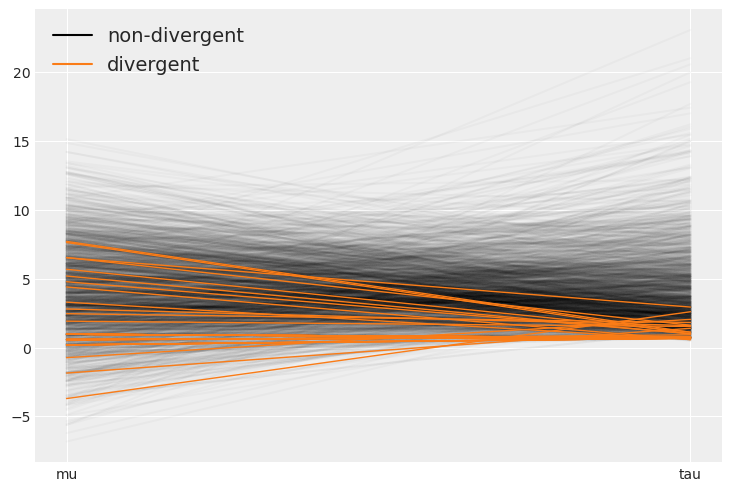
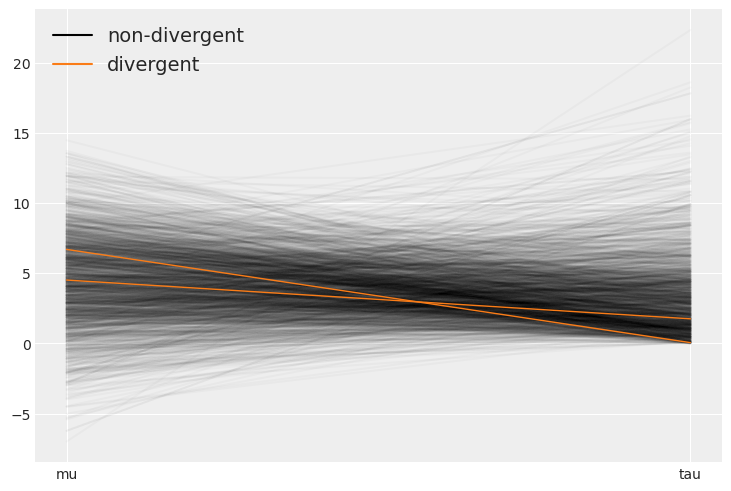
b. Use az.plot_parallel to identify where the divergences tend to concentrate in the parameter space.
The divergences can be counted by accessing the divergences boolean array in the sample_stats group. They can be counted using a sum
centered.sample_stats.diverging.sum()
<xarray.DataArray 'diverging' ()> array(43)
- 43
array(43)
non_centered.sample_stats["diverging"].sum()
<xarray.DataArray 'diverging' ()> array(2)
- 2
array(2)
The divergences tend to concentrate around tau=0. The reason for this is covered in the advanced linear regressions chapter.
az.plot_parallel(centered, var_names=["mu", "tau"]);
az.plot_parallel(non_centered, var_names=["mu", "tau"]);
2E6#
In the GitHub repository we have included an InferenceData object with a Poisson model and one with a NegativeBinomial, both models are fitted to the same dataset. Use az.load_arviz_data(.) to load them, and then use ArviZ functions to answer the following questions:
a. Which model provides a better fit to the data? Use the functions az.compare(.) and az.plot_compare(.)
b. Explain why one model provides a better fit than the other. Use az.plot_ppc(.) and az.plot_loo(.)
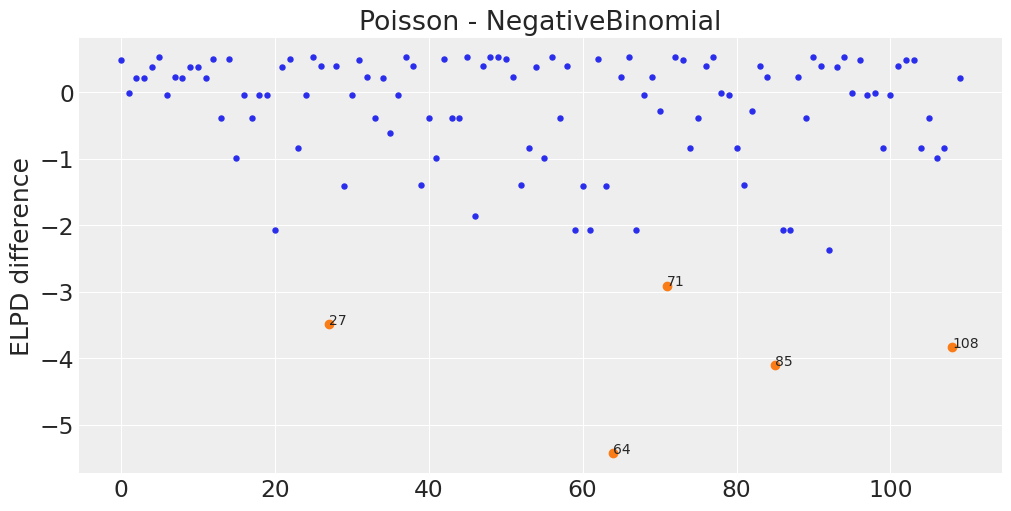
c. Compare both models in terms of their pointwise ELPD values. Identify the 5 observations with the largest (absolute) difference. Which model is predicting them better? For which model p_loo is closer to the actual number of parameters? Could you explain why? Hint: the Poisson model has a single parameter that controls both the variance and mean. Instead, the NegativeBinomial has two parameters.
d. Diagnose LOO using the values. Is there any reason to be concerned about the accuracy of LOO for this particular case?
Inference data generation#
This code is what we’ve used to generate the InferenceData objects in Github. The part that is hidden from students is that Poisson.nc is generated from a model where the data generating distribution matches the likelihood, so it will be a better fit, than InfData2.nc where the data generating process does not match the likelihood.
observed_data = stats.nbinom(5.3, 0.35).rvs(110, random_state=rng)
observed_data
array([11, 14, 13, 13, 12, 10, 6, 7, 13, 12, 12, 13, 9, 5, 9, 17, 6,
5, 6, 6, 2, 12, 9, 4, 6, 10, 8, 22, 8, 18, 6, 11, 7, 5,
13, 16, 6, 10, 8, 3, 5, 17, 9, 5, 5, 10, 19, 8, 10, 10, 9,
7, 3, 4, 12, 17, 10, 5, 8, 2, 18, 2, 9, 18, 25, 7, 10, 2,
6, 7, 15, 21, 10, 11, 4, 5, 8, 10, 14, 6, 4, 3, 15, 8, 7,
23, 2, 2, 7, 5, 10, 8, 20, 12, 10, 14, 11, 6, 14, 4, 6, 8,
11, 11, 4, 5, 17, 4, 0, 13])
with pm.Model() as poisson_model:
lam = pm.HalfNormal("lam", 20)
y = pm.Poisson("y", lam, observed=observed_data)
poisson_inf_data = pm.sample(return_inferencedata=True, random_seed=0)
poisson_inf_data.add_groups({"posterior_predictive": {"y":pm.sample_posterior_predictive(poisson_inf_data,random_seed=0)["y"][None,:]}})
poisson_inf_data.to_netcdf("pois_idata.nc")
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [lam]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 2 seconds.
'pois_idata.nc'
with pm.Model() as negative_model:
alpha = pm.HalfNormal("alpha", 20)
mu = pm.HalfNormal("mu", 20)
y = pm.NegativeBinomial("y", mu, alpha, observed=observed_data)
negative_binom_inf_data = pm.sample(return_inferencedata=True, random_seed=0)
negative_binom_inf_data.add_groups({"posterior_predictive": {"y":pm.sample_posterior_predictive(negative_binom_inf_data,random_seed=0)["y"][None,:]}})
negative_binom_inf_data.to_netcdf("neg_idata.nc")
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [mu, alpha]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 2 seconds.
'neg_idata.nc'
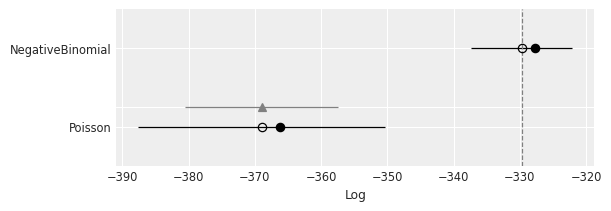
Solution a#
The NegativeBinomial model has a better fit as indicated by the ELPD
pois_idata = az.from_netcdf("pois_idata.nc")
neg_idata = az.from_netcdf("neg_idata.nc")
compare = az.compare({"Poisson":pois_idata, "NegativeBinomial":neg_idata})
compare
/u/32/martino5/unix/anaconda3/envs/pymcv3/lib/python3.9/site-packages/arviz/stats/stats.py:145: UserWarning: The default method used to estimate the weights for each model,has changed from BB-pseudo-BMA to stacking
warnings.warn(
| rank | loo | p_loo | d_loo | weight | se | dse | warning | loo_scale | |
|---|---|---|---|---|---|---|---|---|---|
| NegativeBinomial | 0 | -329.677447 | 2.021825 | 0.000000 | 1.0 | 7.629971 | 0.000000 | False | log |
| Poisson | 1 | -368.983801 | 2.747281 | 39.306354 | 0.0 | 18.629018 | 11.574633 | False | log |
az.plot_compare(compare);
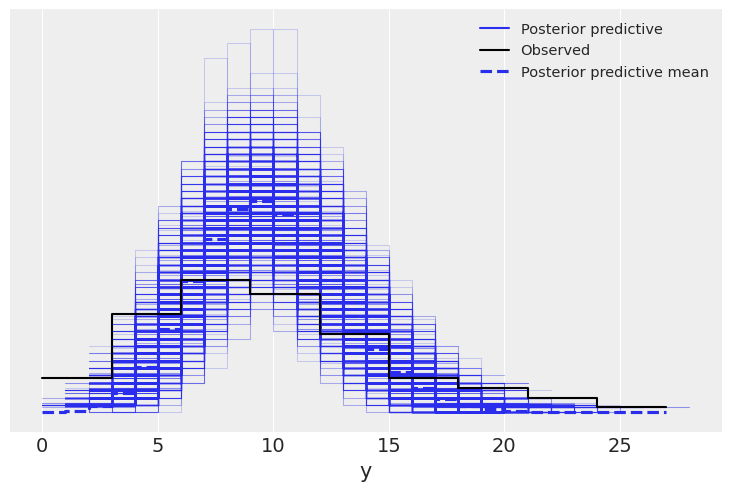
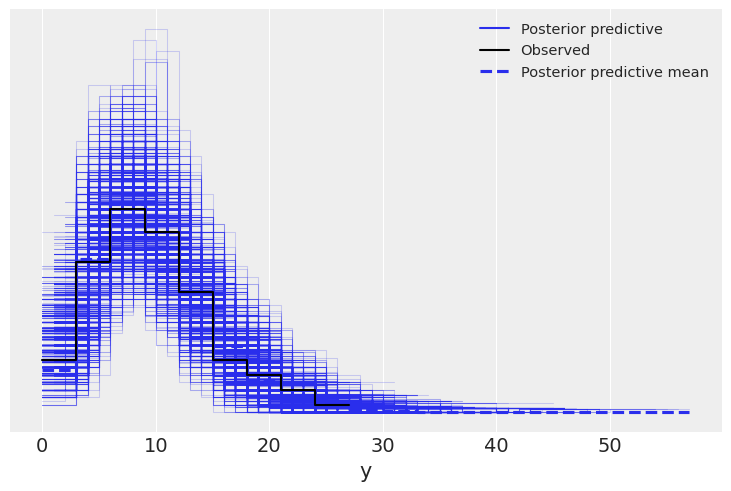
Solution b#
az.plot_ppc(pois_idata);
az.plot_ppc(neg_idata);
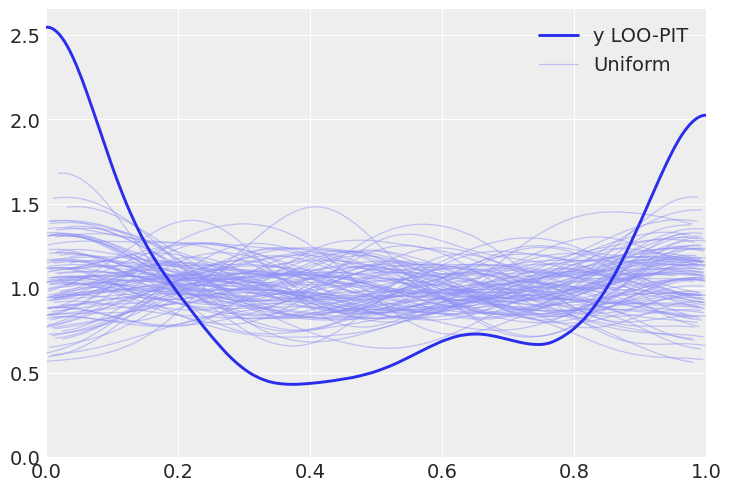
az.plot_loo_pit(pois_idata, y="y");
az.plot_loo_pit(neg_idata, y="y");
Solution c#
pois_elpddata = az.loo(pois_idata, pointwise=True)
pois_elpddata
Computed from 4000 by 110 log-likelihood matrix
Estimate SE
elpd_loo -368.98 18.63
p_loo 2.75 -
------
Pareto k diagnostic values:
Count Pct.
(-Inf, 0.5] (good) 110 100.0%
(0.5, 0.7] (ok) 0 0.0%
(0.7, 1] (bad) 0 0.0%
(1, Inf) (very bad) 0 0.0%
neg_elpddata = az.loo(neg_idata, pointwise=True)
neg_elpddata
Computed from 4000 by 110 log-likelihood matrix
Estimate SE
elpd_loo -329.68 7.63
p_loo 2.02 -
------
Pareto k diagnostic values:
Count Pct.
(-Inf, 0.5] (good) 110 100.0%
(0.5, 0.7] (ok) 0 0.0%
(0.7, 1] (bad) 0 0.0%
(1, Inf) (very bad) 0 0.0%
diff = pois_elpddata.loo_i - neg_elpddata.loo_i
max5_absdiff = np.abs(diff).argsort()[-5:]
az.plot_elpd({"Poisson":pois_elpddata, "NegativeBinomial":neg_elpddata}, figsize=(10, 5),
plot_kwargs={"marker":"."});
plt.plot(max5_absdiff.values, diff[max5_absdiff.values], "C1o");
for x, y in zip(max5_absdiff.values, diff[max5_absdiff.values].values):
plt.text(x, y, x)
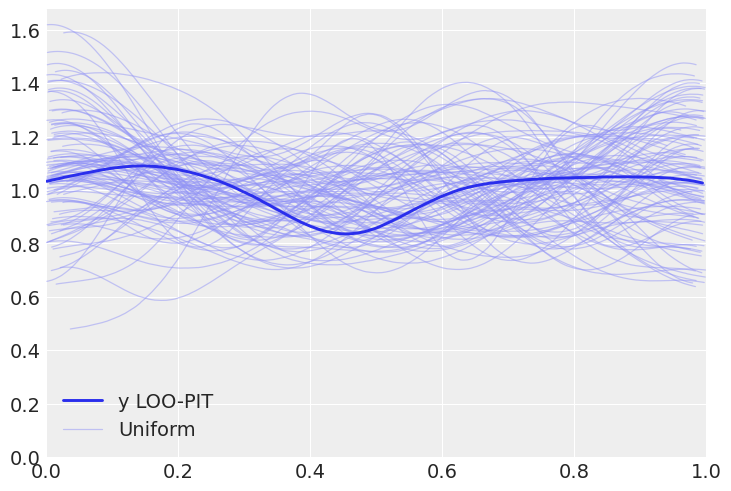
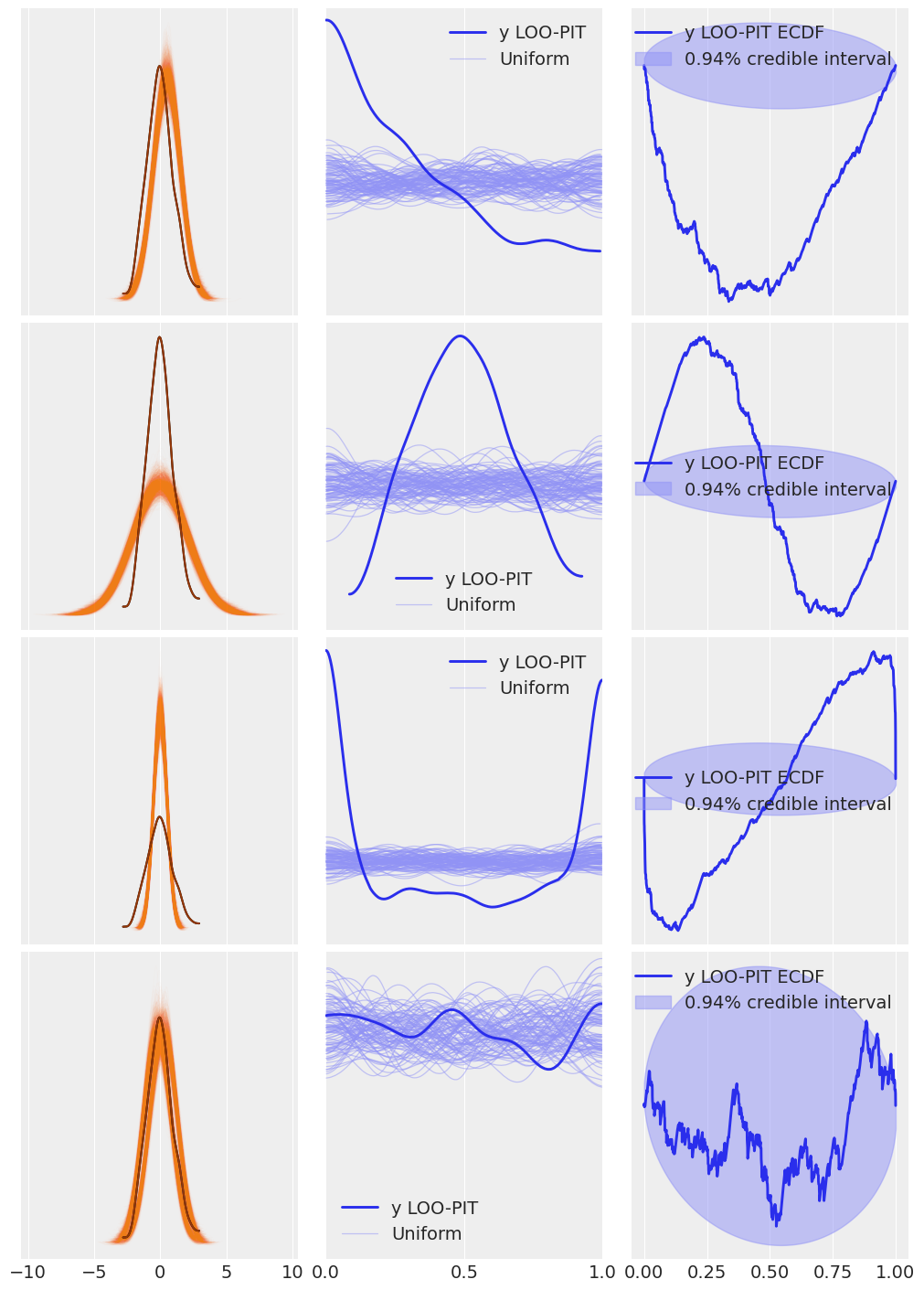
2E7#
Reproduce Fig. 2.7, but using az.plot_loo_pit(ecdf=True) in place of az.plot_bpv(.). Interpret the results. Hint: when using the option ecdf=True, instead of the LOO-PIT KDE you will get a plot of the difference between the LOO-PIT Empirical Cumulative Distribution Function (ECDF) and the Uniform CDF. The ideal plot will be one with a difference of zero.
n_obs = 500
samples = 2000
y_obs = np.random.normal(0, 1, size=n_obs)
apu = 0.025 # arbitrary posterior uncertainty
pp_samples = np.random.normal(0.5, 1, size=(1, samples, n_obs))
log_likelihood = [stats.norm(np.random.normal(0.5, apu),
np.random.normal(1, apu)).logpdf(y_obs)
for i in range(samples)]
log_likelihood = np.array(log_likelihood)[None,:,:]
idata1 = az.from_dict(posterior_predictive={"y":pp_samples},
posterior={"a":0}, # dummy posterior, loo_pit gets the number of chains from the posterior
log_likelihood={"y":log_likelihood},
observed_data={"y":y_obs})
pp_samples = np.random.normal(0, 2, size=(1, samples, n_obs))
log_likelihood = [stats.norm(np.random.normal(0, apu),
np.random.normal(2, apu)).logpdf(y_obs)
for i in range(samples)]
log_likelihood = np.array(log_likelihood)[None,:,:]
idata2 = az.from_dict(posterior_predictive={"y":pp_samples},
posterior={"a":0}, # dummy posterior, loo_pit gets the number of chains from the posterior
log_likelihood={"y":log_likelihood},
observed_data={"y":y_obs})
pp_samples = np.random.normal(0, 0.5, size=(1, samples, n_obs))
log_likelihood = [stats.norm(np.random.normal(0, apu),
np.random.normal(0.5, apu)).logpdf(y_obs)
for i in range(samples)]
log_likelihood = np.array(log_likelihood)[None,:,:]
idata3 = az.from_dict(posterior_predictive={"y":pp_samples},
posterior={"a":0}, # dummy posterior, loo_pit gets the number of chains from the posterior
log_likelihood={"y":log_likelihood},
observed_data={"y":y_obs})
pp_samples = np.concatenate([np.random.normal(-0.25, 1, size=(1, samples//2, n_obs)),
np.random.normal(0.25, 1, size=(1, samples//2, n_obs))],
axis=1)
log_likelihood0 = [stats.norm(np.random.normal(-0.25, apu),
np.random.normal(1, apu)).logpdf(y_obs)
for i in range(samples//2)]
log_likelihood1 = [stats.norm(np.random.normal(0.25, apu),
np.random.normal(1, apu)).logpdf(y_obs)
for i in range(samples//2)]
log_likelihood = np.array(np.concatenate([log_likelihood0, log_likelihood1]))[None,:,:]
idata4 = az.from_dict(posterior_predictive={"y":pp_samples},
posterior={"a":0}, # dummy posterior, loo_pit gets the number of chains from the posterior
log_likelihood={"y":log_likelihood},
observed_data={"y":y_obs})
idatas = [idata1,
idata2,
idata3,
idata4,
]
_, axes = plt.subplots(len(idatas), 3, figsize=(10, 14), sharex="col")
for idata, ax in zip(idatas, axes):
az.plot_ppc(idata, ax=ax[0], color="C1", alpha=0.01, mean=False, legend=False)
az.plot_kde(idata.observed_data["y"], ax=ax[0], plot_kwargs={"color":"C4", "zorder":3})
ax[0].set_xlabel("")
az.plot_loo_pit(idata, y="y", ax=ax[1])
ax[1].set_yticks([])
ax[1].set_xticks([0., 0.5, 1.])
az.plot_loo_pit(idata, y="y", ecdf=True, ax=ax[2])
ax[2].set_yticks([])
arviz - WARNING - Shape validation failed: input_shape: (1, 1), minimum_shape: (chains=1, draws=4)
2E8#
MCMC posterior estimation techniques need convergence diagnostics because MCMC is an approximate method to estimate the posterior. MCMC can fail in many ways, in particular being sensitive to the posterior geometry or starting point. Each of the convergence diagnostics assess a different potential failure mode of MCMC and strive to provide information on whether these failure modes occurred.
Conjugate methods do not need convergence diagnostics because there is no idea of convergence to the true posterior. Conjugate methods calcuate the posterior exactly, there is no approximation of the posterior but the exact posterior itself.
2E9#
An example may be energy plots. Reading the documentation states This may help to diagnose poor exploration by gradient-based algorithms like Hamiltonian Monte Carlo methods.
https://arviz-devs.github.io/arviz/api/generated/arviz.plot_energy.html
2E10#
This is an open ended questionm thus we just provide example of possible explanations.
Prior Selection#
Visualizations examples are az.plot_dist or az.plot_posterior (which spite of the name, works also for other distributions than the posterior). Both of these plots show the shape of the prior distributions, and in the case of az.plot_posterior, some statistics like the mean and HDI are included. Numerical quantities can include statistics such as the mean or standard deviation.
MCMC Sampling#
Visualizations here can be trace plots or rank plots to assess convergence. Similarly \(\hat R\) and ESS can help to assess convergence and effectiveness of MCMC samples
Posterior Predictions#
Plot PPC shows the observed values against the PPC which assess the ability of the model to make future estimates. Numerical diagnostics for posterior predictive estimates could include HDI which assess the highest density interval for future observations.
2M11#
We want to model a football league with \(N\) teams. As usual, we start with a simpler version of the model in mind, just a single team. We assume the scores are Poisson distributed according to a scoring rate . We choose the prior \(\text{Gamma}(0.5, 0.00001)\) because this is sometimes recommend as an “objective” prior.
Generate and plot the prior predictive distribution. How reasonable it looks to you?
Use your knowledge of sports in order to refine the prior choice.
Instead of soccer you now want to model basketball. Could you come with a reasonable prior for that instance? Define the prior in a model and generate a prior predictive distribution to validate your intuition. Hint: You can parameterize the Gamma distribution using the rate and shape parameters as in Code Block poisson_football or alternatively using the mean and standard deviation.
with pm.Model() as model:
μ = pm.Gamma("μ", 0.5, 0.00001)
score = pm.Poisson("score", μ)
prior_predictive = pm.sample_prior_predictive()
trace = pm.sample_prior_predictive()
This prior predictive does not seem terribly realistic when plotted. The prior shows that 100k goal/points are possible when in football 10 would be considered a high scoring game
az.plot_dist(prior_predictive["μ"]);
prior_predictive["μ"].mean()
49341.3131151386
We can change the mean and standard deviation of the prior to obtain this much more reasonable distribution
with pm.Model() as model:
μ = pm.Gamma("μ", mu=3, sd=2)
score = pm.Poisson("score", μ)
prior_predictive = pm.sample_prior_predictive()
trace = pm.sample_prior_predictive()
az.plot_dist(prior_predictive["μ"]);
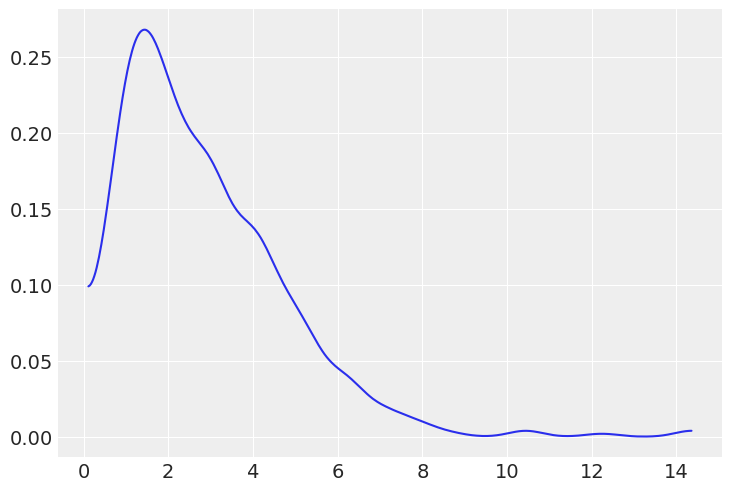
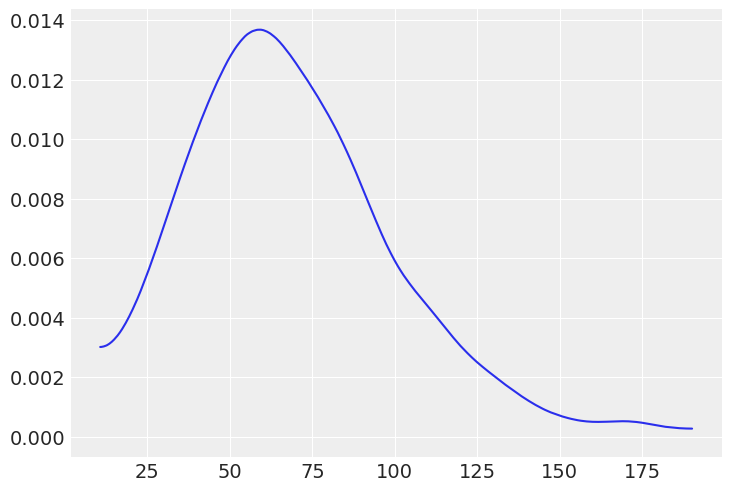
If we create a prior for basketball we could choose a different mu and sd to reflect the scores we’d expect from that sports game
with pm.Model() as model:
μ = pm.Gamma("μ", mu=70, sd=30)
score = pm.Poisson("score", μ)
prior_predictive = pm.sample_prior_predictive()
trace = pm.sample_prior_predictive()
az.plot_dist(prior_predictive["μ"]);
2M12#
In Code Block 1.3 from Chapter 1, change the value of can_sd and run the Metropolis sampler. Try values like 0.2 and 1.
(a) Use ArviZ to compare the sampled values using diagnostics such as the autocorrelation plot, trace plot and the ESS. Explain the observed differences.
(b) Modify Code Block 1.3 so you get more than one independent chain. Use ArviZ to compute rank plots and \(\hat R\).
Solution A#
θ_true = 0.7
rng = np.random.default_rng(2021)
Y = stats.bernoulli(θ_true).rvs(20, random_state=rng)
def post(θ, Y, α=1, β=1):
if 0 <= θ <= 1:
prior = stats.beta(α, β).pdf(θ)
like = stats.bernoulli(θ).pmf(Y).prod()
prop = like * prior
else:
prop = -np.inf
return prop
def sampler(can_sd):
n_iters = 1000
α = β = 1
θ = 0.5
trace = {'θ':np.zeros(n_iters)}
p2 = post(θ, Y, α, β)
for iter in range(n_iters):
θ_can = stats.norm(θ, can_sd).rvs(1)
p1 = post(θ_can, Y, α, β)
pa = p1 / p2
if pa > stats.uniform(0, 1).rvs(1):
θ = θ_can
p2 = p1
trace['θ'][iter] = θ
return trace
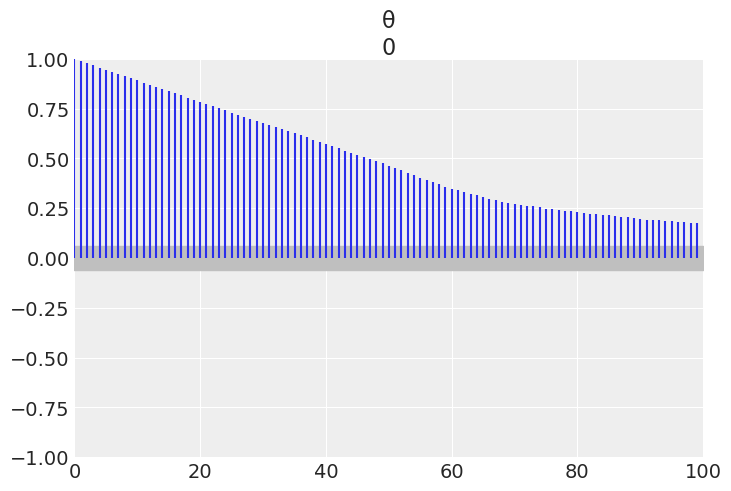
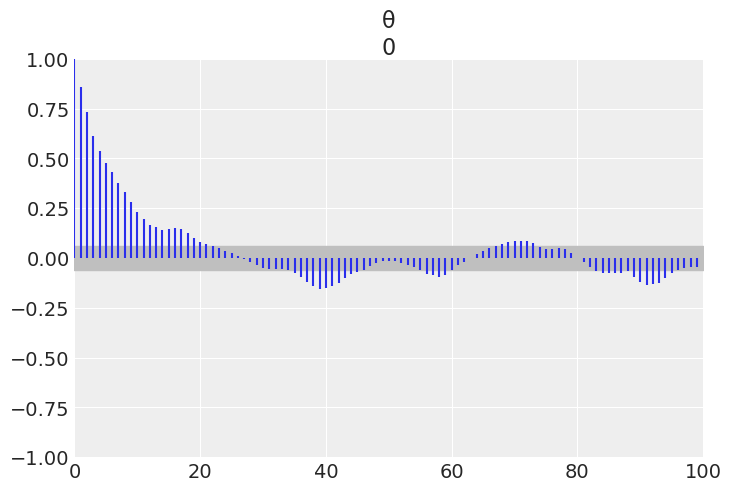
trace_02 = sampler(.02)
trace_1 = sampler(1)
Below we have the trace plot, ess, and autocorrelation plot. Changing the parameter can_sd changes the distribution of step size of the sampler which can be seen in each of the plots below.
a) In the trace plot for can_sd=.02 the stepped size is more “jagged” as each time the candidate value of \(\theta\) changes, its only by a little. In the trace plot for can_sd=1 the steps are more pronounced with the sampler taking a larger step each time
b) In the ESS calculation for can_sd=.02 the samples are much more correlated versus the can_sd=1. The larger step size induces less autocorrelation than the smaller sample size.
c) Plot C confirms the results of the ESS calculation. With smaller step sizes the correlation of samples is higher as the value of the current step won’t be much different than the upcoming step.
az.plot_trace(trace_02);

az.plot_trace(trace_1);

(<xarray.Dataset>
Dimensions: ()
Data variables:
θ float64 13.43,
<xarray.Dataset>
Dimensions: ()
Data variables:
θ float64 71.21)
az.plot_autocorr(trace_02);
az.plot_autocorr(trace_1);
2M13#
Generate a random sample using np.random.binomial(n=1, p=0.5, size=200) and fit it using a
Beta-Binomial model.
Use pm.sample(., step=pm.Metropolis()) (Metropolis-Hastings sampler) and pm.sample(.) (the standard sampler). Compare the results in terms of the ESS, \(\hat R\), autocorrelation, trace plots and rank plots.
Reading the PyMC3 logging statements what sampler is autoassigned? What is your conclusion about this sampler performance compared to Metropolis-Hastings?
Metropolis Hastings Model#
with pm.Model() as betabinom:
θ = pm.Beta("θ", 1,1)
y = pm.Binomial("y", p=θ, n=1, observed = Y)
trace = pm.sample( step=pm.Metropolis())
<ipython-input-54-8e3b93d28c90>:4: FutureWarning: In v4.0, pm.sample will return an `arviz.InferenceData` object instead of a `MultiTrace` by default. You can pass return_inferencedata=True or return_inferencedata=False to be safe and silence this warning.
trace = pm.sample( step=pm.Metropolis())
Multiprocess sampling (4 chains in 4 jobs)
Metropolis: [θ]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 1 seconds.
The number of effective samples is smaller than 25% for some parameters.
az.summary(trace)
/u/32/martino5/unix/anaconda3/envs/pymcv3/lib/python3.9/site-packages/arviz/data/io_pymc3.py:96: FutureWarning: Using `from_pymc3` without the model will be deprecated in a future release. Not using the model will return less accurate and less useful results. Make sure you use the model argument or call from_pymc3 within a model context.
warnings.warn(
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| θ | 0.593 | 0.098 | 0.414 | 0.772 | 0.004 | 0.003 | 774.0 | 1197.0 | 1.01 |
az.plot_autocorr(trace);
/u/32/martino5/unix/anaconda3/envs/pymcv3/lib/python3.9/site-packages/arviz/data/io_pymc3.py:96: FutureWarning: Using `from_pymc3` without the model will be deprecated in a future release. Not using the model will return less accurate and less useful results. Make sure you use the model argument or call from_pymc3 within a model context.
warnings.warn(

az.plot_trace(trace);
/u/32/martino5/unix/anaconda3/envs/pymcv3/lib/python3.9/site-packages/arviz/data/io_pymc3.py:96: FutureWarning: Using `from_pymc3` without the model will be deprecated in a future release. Not using the model will return less accurate and less useful results. Make sure you use the model argument or call from_pymc3 within a model context.
warnings.warn(

az.plot_rank(trace);
/u/32/martino5/unix/anaconda3/envs/pymcv3/lib/python3.9/site-packages/arviz/data/io_pymc3.py:96: FutureWarning: Using `from_pymc3` without the model will be deprecated in a future release. Not using the model will return less accurate and less useful results. Make sure you use the model argument or call from_pymc3 within a model context.
warnings.warn(
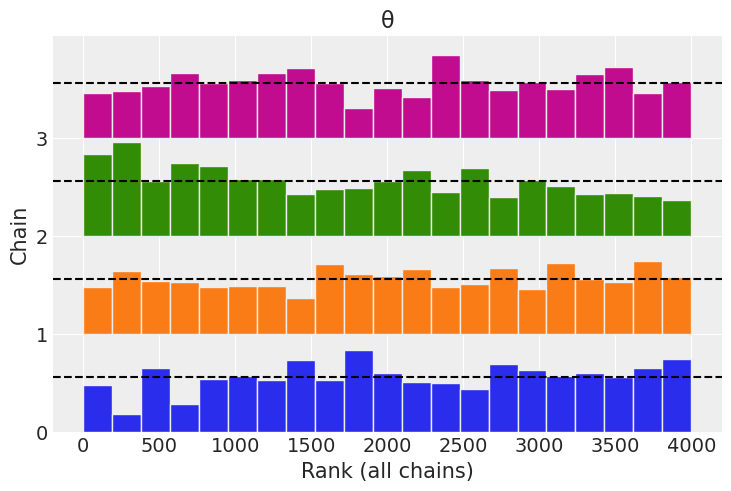
Default Sampler (HMC)#
with pm.Model() as betabinom:
θ = pm.Beta("θ", 1,1)
y = pm.Binomial("y", p=θ, n=1, observed = Y)
trace = pm.sample()
<ipython-input-59-bae42eb2b82e>:4: FutureWarning: In v4.0, pm.sample will return an `arviz.InferenceData` object instead of a `MultiTrace` by default. You can pass return_inferencedata=True or return_inferencedata=False to be safe and silence this warning.
trace = pm.sample()
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [θ]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 2 seconds.
az.summary(trace)
/u/32/martino5/unix/anaconda3/envs/pymcv3/lib/python3.9/site-packages/arviz/data/io_pymc3.py:96: FutureWarning: Using `from_pymc3` without the model will be deprecated in a future release. Not using the model will return less accurate and less useful results. Make sure you use the model argument or call from_pymc3 within a model context.
warnings.warn(
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| θ | 0.592 | 0.102 | 0.406 | 0.785 | 0.002 | 0.002 | 1834.0 | 2693.0 | 1.0 |
az.plot_autocorr(trace);
/u/32/martino5/unix/anaconda3/envs/pymcv3/lib/python3.9/site-packages/arviz/data/io_pymc3.py:96: FutureWarning: Using `from_pymc3` without the model will be deprecated in a future release. Not using the model will return less accurate and less useful results. Make sure you use the model argument or call from_pymc3 within a model context.
warnings.warn(

az.plot_trace(trace);
/u/32/martino5/unix/anaconda3/envs/pymcv3/lib/python3.9/site-packages/arviz/data/io_pymc3.py:96: FutureWarning: Using `from_pymc3` without the model will be deprecated in a future release. Not using the model will return less accurate and less useful results. Make sure you use the model argument or call from_pymc3 within a model context.
warnings.warn(

az.plot_rank(trace);
/u/32/martino5/unix/anaconda3/envs/pymcv3/lib/python3.9/site-packages/arviz/data/io_pymc3.py:96: FutureWarning: Using `from_pymc3` without the model will be deprecated in a future release. Not using the model will return less accurate and less useful results. Make sure you use the model argument or call from_pymc3 within a model context.
warnings.warn(
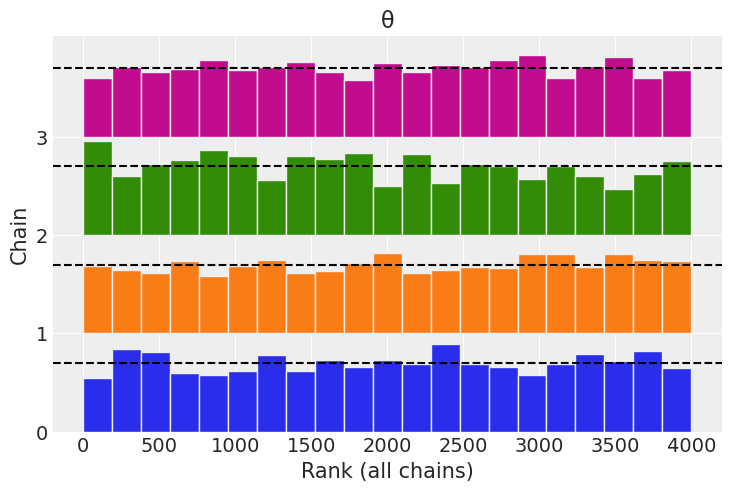
2M14#
Generate your own example of a synthetic
posterior with convergence issues, let us call it bad_chains3.
a. Explain why the synthetic posterior you generated is “bad”. What about it would we not want to see in an actual modeling scenario?
b. Run the same diagnostics we run in the book for bad_chains0 and
bad_chains1. Compare your results with those in the book and
explain the differences and similarities.
c. Did the results of the diagnostics from the previous point made you
reconsider why bad_chains3 is a “bad chain”?
Let us generate two types of bad chains. The first is a chain that linearly gets larger. The second is a chain that that is just a sin wave generated from the first trace. Neither of these chains are randomly samping any space, and the values they are producing are not from the same underlying function.
(2, 1000)
Plotting a number of diagnostics we can get a sense of the issues. In a rank plot we get a sense that if we sort the samples across plot chains, and then plot their rank, that the sample from the linearly growing chain are all larger than the values from the sin wave, hences hte lack of uniformity,
az.plot_rank(chains);
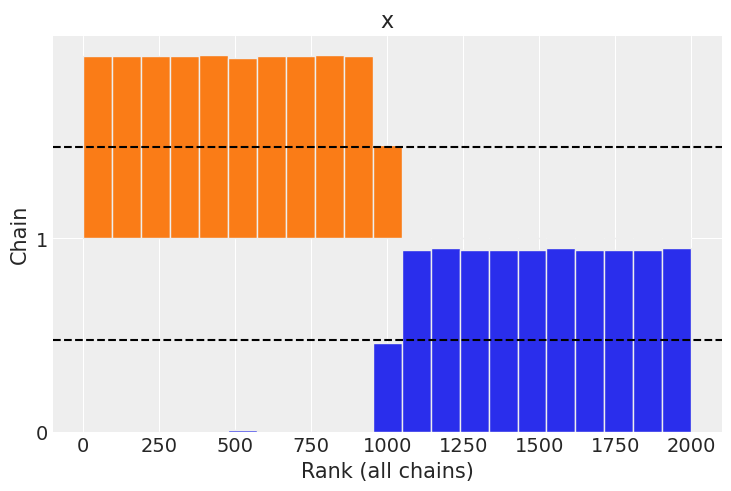
The autocorrelation plot is similar in that for the linearly growing chain the linear autocorrelation is present throughout the chain, versus in the sinusoidal chain the there is a regular recurring linear autocorrelation.
az.plot_autocorr(chains);
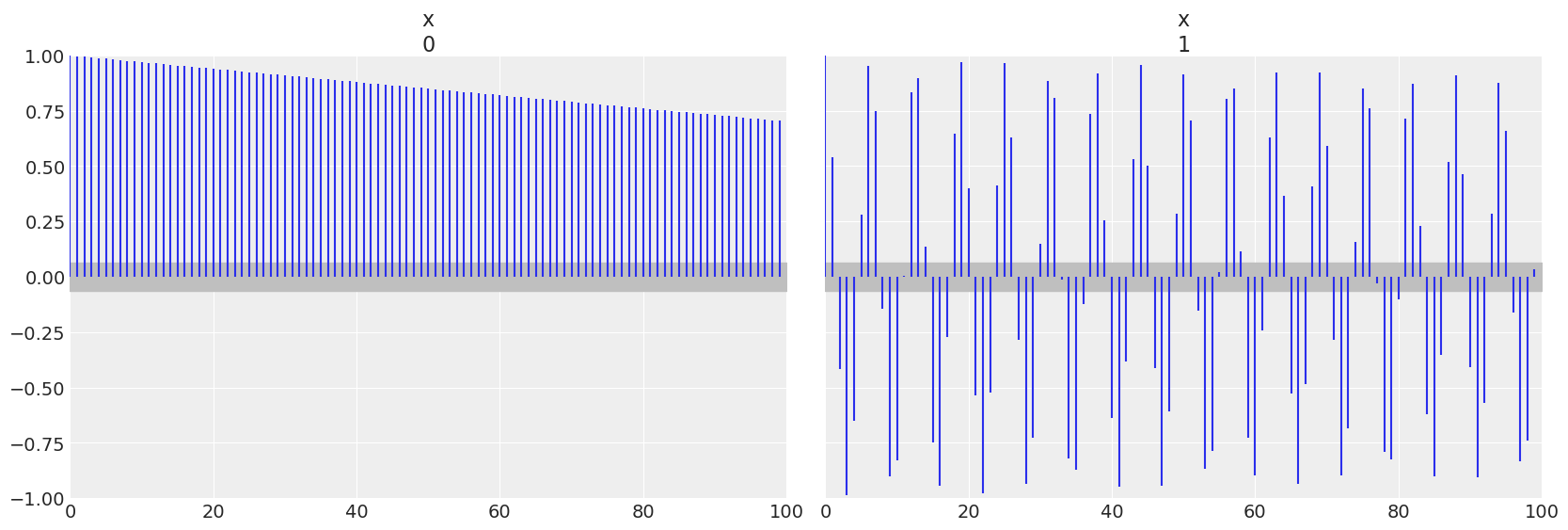
Rhat also confirms the variance of these two sets of values is not similar to each other.
az.rhat(chains)
2.2272918677093814
2M15#
Generate a random sample using np.random.binomial(n=1, p=0.5, size=200) and fit it using a Beta-Binomial model.
a. Check that LOO-PIT is approximately Uniform.
b. Tweak the prior to make the model a bad fit and get a LOO-PIT that is low for values closer to zero and high for values closer to one. Justify your prior choice.
c. Tweak the prior to make the model a bad fit and get a LOO-PIT that is high for values closer to zero and low for values closer to one. Justify your prior choice.
d. Tweak the prior to make the model a bad fit and get a LOO-PIT that is high for values close to 0.5 and low for values closer to zero and one. Could you do it? Explain why.
Y = np.random.binomial(n=1, p=0.5, size=200)
Y
array([0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0, 1, 1, 0, 0, 0, 1, 1, 1,
0, 0, 1, 0, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 0, 1, 0,
1, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 1, 1, 0, 0, 1, 1,
0, 1, 1, 1, 1, 0, 1, 1, 0, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1,
0, 0, 1, 1, 1, 1, 0, 0, 1, 1, 0, 1, 0, 1, 0, 0, 0, 1, 1, 1, 1, 0,
0, 1, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 1, 1, 0, 0, 0, 1, 1, 0,
0, 0, 1, 0, 0, 1, 1, 1, 0, 0, 1, 0, 0, 0, 1, 0, 1, 0, 1, 0, 1, 0,
0, 1, 0, 0, 1, 1, 1, 1, 0, 1, 0, 0, 0, 1, 0, 1, 1, 1, 0, 0, 1, 0,
0, 0, 0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 1,
0, 0])
with pm.Model() as betabinom:
θ = pm.Beta("θ", 1,1)
y = pm.Binomial("y", p=θ, n=1, observed = Y)
trace = pm.sample()
posterior_predictive = pm.sample_posterior_predictive(trace)
inf_data = az.from_pymc3(trace=trace, posterior_predictive=posterior_predictive)
<ipython-input-69-0c047e0004e5>:4: FutureWarning: In v4.0, pm.sample will return an `arviz.InferenceData` object instead of a `MultiTrace` by default. You can pass return_inferencedata=True or return_inferencedata=False to be safe and silence this warning.
trace = pm.sample()
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [θ]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 2 seconds.
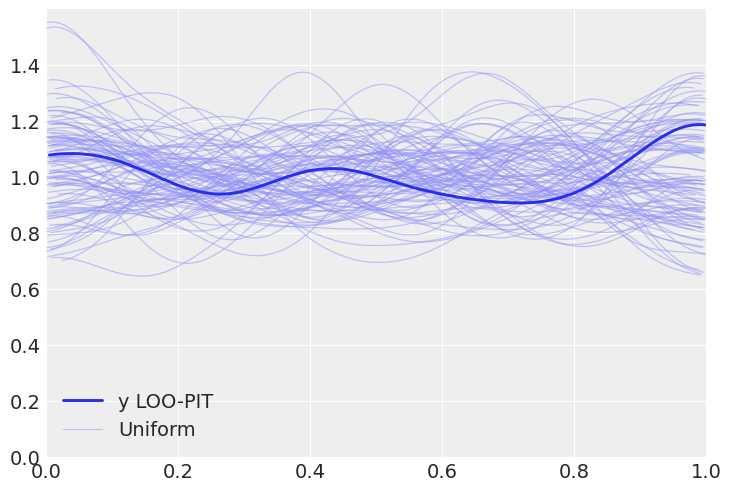
Solution A#
az.plot_loo_pit(inf_data, y="y");
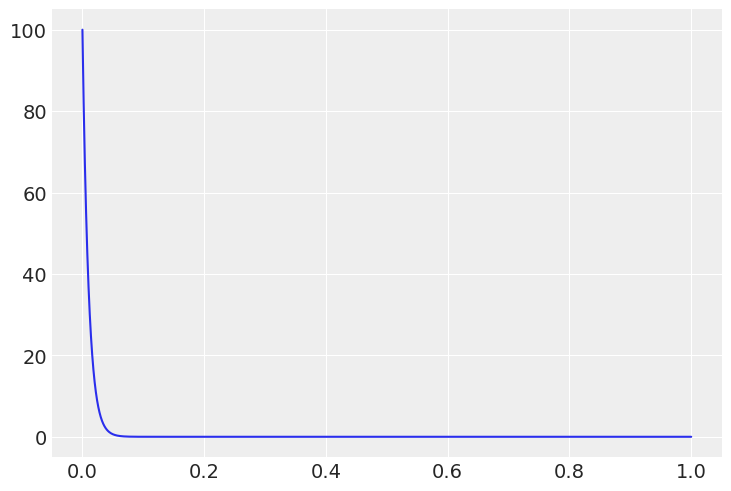
Solution B#
The justification is easier with with plotting the prior. With the prior below we are indicating that were expecting
x = np.linspace(0,1,999)
θ = stats.beta(1, 100).pdf(x)
plt.plot(x, θ);
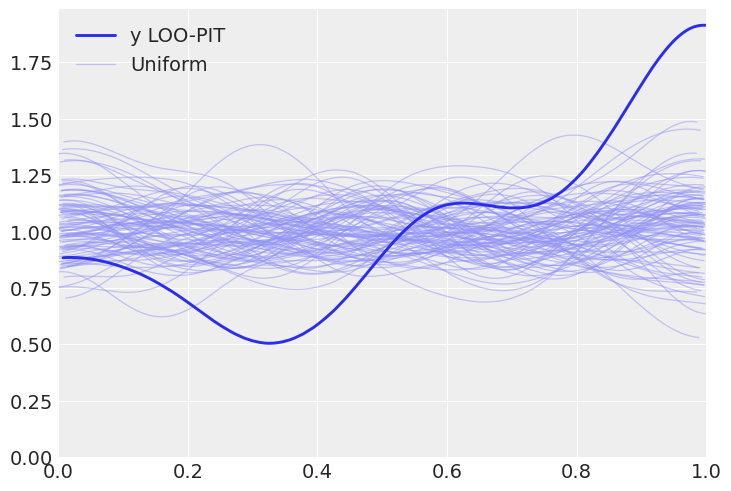
with pm.Model() as betabinom:
θ = pm.Beta("θ", 1, 100)
y = pm.Binomial("y", p=θ, n=1, observed = Y)
trace = pm.sample()
posterior_predictive = pm.sample_posterior_predictive(trace)
inf_data = az.from_pymc3(trace=trace, posterior_predictive=posterior_predictive)
az.plot_loo_pit(inf_data, y="y")
<ipython-input-72-5afcaa064613>:4: FutureWarning: In v4.0, pm.sample will return an `arviz.InferenceData` object instead of a `MultiTrace` by default. You can pass return_inferencedata=True or return_inferencedata=False to be safe and silence this warning.
trace = pm.sample()
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [θ]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 2 seconds.
<AxesSubplot:>
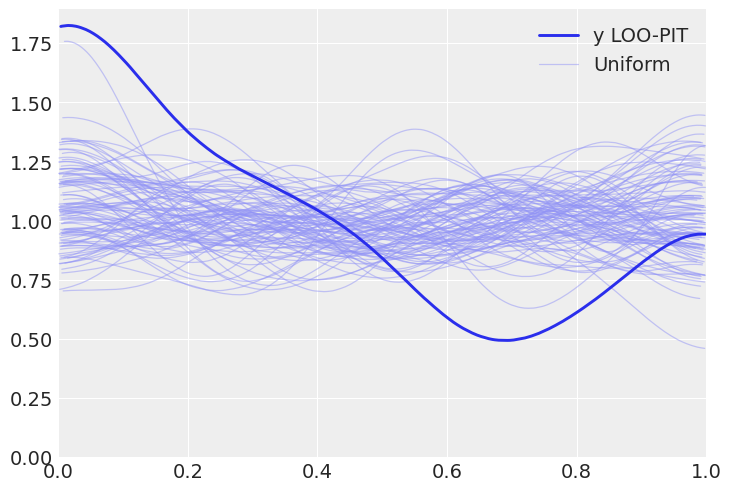
Solution C#
with pm.Model() as betabinom:
θ = pm.Beta("θ", 100, 1)
y = pm.Binomial("y", p=θ, n=1, observed = Y)
trace = pm.sample()
posterior_predictive = pm.sample_posterior_predictive(trace)
inf_data = az.from_pymc3(trace=trace, posterior_predictive=posterior_predictive)
az.plot_loo_pit(inf_data, y="y");
<ipython-input-73-63ac115a1361>:4: FutureWarning: In v4.0, pm.sample will return an `arviz.InferenceData` object instead of a `MultiTrace` by default. You can pass return_inferencedata=True or return_inferencedata=False to be safe and silence this warning.
trace = pm.sample()
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [θ]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 2 seconds.
Solution D#
With a Beta-binomial model we only can have more 0s than expected or more 1s than expected. Is not possible to have more/less “bulk” values than expected or more/less “tail” values than expected
2H16#
Use PyMC3 to write a model with Normal likelihood. Use the following random samples as data and the following priors for the mean. Fix the standard deviation parameter in the likelihood at 1.
a. A random sample of size 200 from a \(\mathcal{N}(0,1)\) and prior distribution \(\mathcal{N}(0,20)\)
b. A random sample of size 2 from a \(\mathcal{N}(0,1)\) and prior distribution \(\mathcal{N}(0,20)\)
c. A random sample of size 200 from a \(\mathcal{N}(0,1)\) and prior distribution \(\mathcal{N}(20, 1)\)
d. A random sample of size 200 from a \(\mathcal{U}(0,1)\) and prior distribution \(\mathcal{N}(10, 20)\)
e. A random sample of size 200 from a \(\mathcal{HN}(0,1)\) and a prior distribution \(\mathcal{N}(10,20)\)
Assess convergence by running the same diagnostics we run in the book
for bad_chains0 and bad_chains1. Compare your results with those in
the book and explain the differences and similarities.
Note: This exercise is still unfinished. Models are defined but convergence assessment is missing. Feel free to contribute a solution by sending a PR.
Solution A#
y = stats.norm(0, 1).rvs(200)
with pm.Model() as model_2h16a:
mu = pm.Normal("mu", 0, 20)
y = pm.Normal("y", mu, 1, observed=y)
Solution B#
y = stats.norm(0, 1).rvs(2)
with pm.Model() as model_2h16b:
mu = pm.Normal("mu", 0, 20)
y = pm.Normal("y", mu, 1, observed=y)
Solution C#
y = stats.norm(0,1).rvs(200)
with pm.Model() as model_2h16b:
mu = pm.Normal("mu", 20, 1)
y = pm.Normal("y", mu, 1, observed=y)
Solution D#
y = stats.uniform(0,1).rvs(200)
with pm.Model() as model_2h16c:
mu = pm.Normal("mu", 10, 20)
y = pm.Normal("y", mu, 1, observed=y)
Solution E#
y = stats.halfnorm(0,1).rvs(200)
with pm.Model() as model_2h16d:
mu = pm.Normal("mu", 10,20)
y = pm.Normal("y", mu, 1, observed=y)
2H17#
Each of the four sections in this chapter, prior predictive checks, posterior predictive checks, numerical inference diagnostics, and model comparison, detail a specific step in the Bayesian workflow. In your own words explain what the purpose of each step is, and conversely what is lacking if the step is omitted. What does each tell us about our statistical models?
prior predictive checks: Assseses a couple of things. One is if our model is specified at least correctly enough to sample in the absence of data. Another is check the match or mismatch with our domain knowledge. If we omit prior predictive checks we may not understand how our choices of prior map to the domain of the observed data.
Posterior Predictive Checks: After our model is conditioned on data, what the future observations may look like. Posterior predictive checks also help us assess the fit of our model against the observed data, and highlight issues as a whole or in particular regions of the observed space. If we omit posterior predictive checks may not understand how the conditioned parameter distributions map to the domain of the observed data.
Numerical Inference Diagnostics: After we perform sampling we need to check if our sampler was successful. Posterior sampling is error prone and not guaranteed to converge to a correct or usable posterior estimate. If we skip this step any inferences we make may be completely wrong, perhaps because our sampler failed, our model was mispecified, or our data was faulty in some manner.
Model Comparison: Model comparison is useful any time we have more than one model, is a situation that should occur often. A model itsellf is not a fact but an assumption, and by comparing two models it can yield insights into the strengths and weaknesses of each one. Model comparison can tell us which models are able to make better estimates of the data, which ones complexity are not justified by their predictive performance.